10 Most Frequently Asked Python List Questions on Stack Overflow

Stack Overflow is a gold mine of information where you can find thousands of questions and answers in software, coding, Data Science, and many other subjects.
If you ask content creators about what kind of mistakes they expect students to make when solving their questions or what would be difficult for students to understand, you'd be surprised how content creators fail to make an accurate guess.
I mentioned this to make a point on how valuable the information on Stack Overflow is. The questions on Stack Overflow come from people trying to solve an issue in their jobs or making a mistake while using a software tool. Thus, Stack Overflow reflects the challenges in real-life, and does so very accurately.
After going over the top questions on Pandas and Python dictionaries, in this article, we will go through the 10 most frequently asked Python list questions on Stack Overflow.
List **** is a built-in data structure in Python. It is represented as a collection of data points in square brackets and can be used for storing data of different types.
I searched for the questions using "python" and "list" tags and sorted them by score.
Let's start.
1. Accessing the index in ‘for' loops
This question can be generalized to other iterables such as tuples and strings. It's basically asking how to get the index of an item along with the item itself.
The simplest and Pythonic answer to this question is to use the enumerate function, which returns a tuple containing a count and the values obtained from iterating over iterable.
names = ["John", "Jane", "Ashley"]
for idx, x in enumerate(names):
print(idx, x)
# output
0 John
1 Jane
2 AshleyThe count starts from 0 by default but it can be changed using the start parameter.
names = ["John", "Jane", "Ashley"]
for idx, x in enumerate(names, start=10):
print(idx, x)
# output
10 John
11 Jane
12 Ashley2. How do I make a flat list out of a list of lists?
The following drawing illustrates what is being asked in this question:

You can do this conversion by using a list comprehension as follows:
# using list comprehension
mylist = [
[1, 5, 3],
[4, 2, 1],
[5, 6]
]
myflatlist = [item for sublist in mylist for item in sublist]
print(myflatlist)
# output
[1, 5, 3, 4, 2, 1, 5, 6]The list comprehension above can also be written as nested for loops. It's more intuitive and easier to understand but list comprehension is more performant especially when working with large lists.
# using for loops
mylist = [
[1, 5, 3],
[4, 2, 1],
[5, 6]
]
myflatlist = []
for sublist in mylist:
for item in sublist:
myflatlist.append(item)
print(myflatlist)
# output
[1, 5, 3, 4, 2, 1, 5, 6]If you're using Pandas, the explode function makes this flattening operation quite easy but you need to convert the list to a Pandas series first. If you want the final output to be a list, then you can convert the output of the explode function to a list using the list constructor.
# using the explode function
import pandas as pd
myflatlist = list(pd.Series(mylist).explode())
print(myflatlist)
# output
[1, 5, 3, 4, 2, 1, 5, 6]3. Finding the index of an item in a list
The index of an item can be used for accessing the item in a list. Here is an example to show this case:
names = ["John", "Jane", "Ashley", "Max", "Jane"]
# item with index 2 (i.e. the third item)
names[2]
# output
'Ashley'The item with index 2 is the third item because index starts from 0.
The question is asking how to find that index, which can be done using the built-in index method.
names = ["John", "Jane", "Ashley", "Max", "Jane"]
names.index("Ashley")
# output
2Starting from the beginning, the index method searches through the list in order until it finds a match, and then stops. Thus, in the case of having multiple occurrences of the same item, the index method returns the index of the first item.
If you want to get the indexes of all occurrences, you can use the enumerate function in a list comprehension as follows:
names = ["John", "Jane", "Ashley", "Max", "Jane", "Abby", "Jane"]
janes_indexes = [idx for idx, item in enumerate(names) if item == "Jane"]
print(janes_indexes)
# output
[1, 4, 6]It returns a list of index values for the given item.
4. How do I concatenate two lists in Python?
You can concatenate lists simply by using the "+" operator.
list_1 = [1, 3, 4]
list_2 = [12, 23, 30]
combined = list_1 + list_2
print(combined)
# output
[1, 3, 4, 12, 23, 30]You can also use the extend function. It does not return a combined list but extends the first list with the items in the second list.
list_1 = [1, 3, 4]
list_2 = [12, 23, 30]
list_1.extend(list_2)
print(list_1) # list_1 is now the combined list, list_2 remains the same
# output
[1, 3, 4, 12, 23, 30]5. How do I check if a list is empty?
There are different ways of checking if a list is empty.
One option is to use the fact that empty sequences and collections are False , which can be used in an if statement to check if a list is empty.
names = []
if not names:
print("list is not empty!")
# output
list is not empty!You can also use the built-in len function, which returns the number of items in a list. If this value is 0, then the list is empty.
len(names)
# output
06. What is the difference between Python's list methods append and extend?
The append method can be used for adding new items to a list.
names = ["Jane", "Max", "Ashley"]
names.append("John")
print(names)
# output
['Jane', 'Max', 'Ashley', 'John']Whatever the type of the value is, it is added as a new item in the list. So, if you append a list of values, the list becomes a single item.
names = ["Jane", "Max", "Ashley"]
new_names = ["John", "Adam"]
names.append(new_names)
print(names)
# output
['Jane', 'Max', 'Ashley', ['John', 'Adam']]The names list above contains 4 items because "John" and "Adam" are appended as a list so "John" and "Adam" are not the items of the names list.
Let's check if "John" exists in the names list:
"John" in names
# output
FalseThis is where the extend function comes into play. It extends the current list with the items in the new list. If you do the example above using the extend function, you'll see that "John" and "Adam" are added as separate items to the names list.
names = ["Jane", "Max", "Ashley"]
new_names = ["John", "Adam"]
names.extend(new_names)
print(names)
# output
['Jane', 'Max', 'Ashley', 'John', 'Adam']Let's check if "John" exists in names list now:
"John" in names
# output
True7. How do I split a list into equally-sized chunks?
The following drawing illustrates what is being asked in this question:
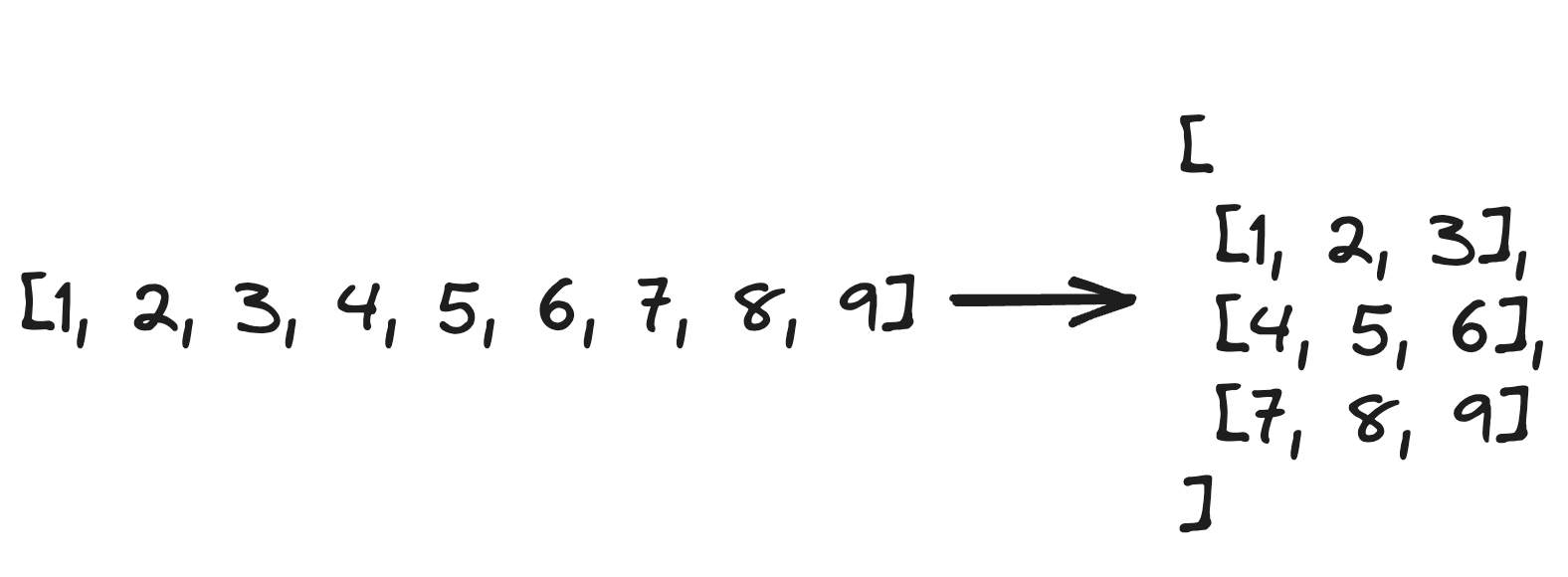
List comprehension can be used for this task.
The first step is to specify a chunk size, which will be used for determining the splitting points.
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
chunk_size = 4
[mylist[i:i + chunk_size] for i in range(0, len(mylist), chunk_size)]
# output
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]Feel free to play around with the chunk size and see how the output changes.
8. How to sort a list of dictionaries by a value of the dictionary in Python?
Let's say you have the following list, which contains dictionaries as its items.
employees = [
{"name": "Max", "department": "sales"},
{"name": "Jane", "department": "engineering"},
{"name": "Ashley", "department": "hr"}
]You want to sort the items (i.e. dictionaries) by names. It can be done using the built-in sorted function of Pandas. To sort by the names, we need to specify it using the key parameter.
employees_sorted = sorted(employees, key = lambda x: x["name"])
employees_sorted
# output
[{'name': 'Ashley', 'department': 'hr'},
{'name': 'Jane', 'department': 'engineering'},
{'name': 'Max', 'department': 'sales'}]The key parameter defines how to sort the items. In this case, the lambda expression is used for extracting the names from dictionaries, which are then used for sorting.
9. How do I get the last element of a list?
The simplest way is to use indexes.
The index of the first item is 0. You can also start the index from the end. In that case, index of the first item (i.e. the last item of the list) is -1.
names = ["Jane", "Adam", "Matt", "Jennifer"]
names[-1]
# output
'Jennifer'
names[0]
# output
'Jane'10. How can I randomly select an item from a list?
The random module of Python can be used for this task.
The choice method randomly selects a single item.
import random
names = ["Jane", "Adam", "Matt", "Jennifer", "Abby"]
random.choice(names)
# output
'Matt'If you want to take a random sample of n items, you can use the sample method.
import random
names = ["Jane", "Adam", "Matt", "Jennifer", "Abby"]
random.sample(names, 2) # random sample with 2 items
# output
['Abby', 'Matt']Conclusion
List is a frequently used data structure. It's mutable and can hold data of different types, which makes it a great choice for storing and managing data. In order to write efficient programs with Python, you need to learn lists and other built-in data structures (e.g. dictionary, set, tuple) well.
The questions covered in this article come from the challenges people face when working with lists. You may encounter the same issues. Even if you don't, it's still important to know them to better understand the features of lists.
You can become a Medium member to unlock full access to my writing, plus the rest of Medium. If you already are, don't forget to subscribe if you'd like to get an email whenever I publish a new article.
Thank you for reading. Please let me know if you have any feedback.
