Everything You Need To Know About Regularization
If you're working with machine learning models, you've probably heard of regularization. But do you know what it is and how it works? Regularization is a technique used to prevent overfitting and improve the performance of models. In this post, we'll break down the different types of regularization and how you can use them to improve your models. Besides, you learn when to apply the different types.
Regularization in machine learning means ‘simplifying the outcome'. In case a model is overfitting and too complex, you can use regularization to make the model generalize better. You should use regularization if the gap in performance between train and test is big. This means the model grasps too much details of the train set. Overfitting is related to high variance, which means the model is sensitive to specific samples of the train set.

Let's start discussing different regularization techniques. Every technique falls into one of the following two categories: explicit or implicit regularization. It is possible to combine multiple regularization techniques in the same problem.
Explicit Regularization
All techniques that fall into explicit regularization are explicitly adding a term to the problem. We will dive into the three most common types of explicit regularization. These types are L1, L2 and Elastic Net regularization.
As example we take a linear regression model with independent variables x₁ and x₂, and dependent variable y. The model can be represented by the following equation:

We want to determine the weights: w₁, w₂ and b. The cost function is equal to the mean squared error, which we want to minimize. Below the cost function J:

In the following examples, you can see how the cost function changes for different types of explicit regularization.
L1 regularization
This type of regularization is also known as Lasso regularization. It adds a term to the cost function that is proportional to the absolute value of the weight coefficients:

It tends to shrink some of the weight coefficients to zero. The sum of the term is multiplied by lambda, which controls the amount of regularization. If lambda is too high, the model will be simple, and the risk of underfitting arises.
L2 regularization
L2 regularization, or Ridge regularization, adds a term to the cost function that is proportional to the square of the weight coefficients:

This term tends to shrink all of the weight coefficients, but unlike L1 regularization, it does not set any weight coefficients to zero.
Elastic Net regularization
This is a combination of both L1 and L2 regularization. As you would expect, with Elastic Net regularization, both of the L1 and L2 terms are added to the cost function. And a new hyperparameter α is added to control the balance between L1 and L2.
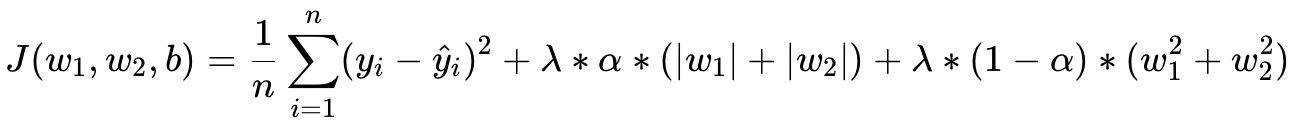
When to use L1, L2 or Elastic Net?
In many scikit-learn models L2 is the default (see LogisticRegression and SupportVectorMachines). This is for a reason: L1 tends to shrink some of the weight coefficients to zero, which means the features are removed from te model. So L1 regularization is more useful for feature selection. To really prevent overfitting, L2 might be the better choice, because it does not set any of the weight coefficients to zero.
Elastic Net regularization is a good choice when you have correlated features and you want to balance the feature selection and overfitting prevention. It's also useful when you're not sure whether L1 or L2 regularization would be more appropriate for your data and model.
In general, L2 regularization is recommended when you have a large number of features and you want to keep most of them in the model, and L1 regularization is recommended when you have a high-dimensional dataset with many correlated features and you want to select a subset of them.
Implicit Regularization
The techniques that aren't explicit, automatically fall into the implicit category. There are many different implicit techniques, here I will discuss some of them that are used often.
Model parameters
An easy way to make a model generalize better is by specifying some of the model hyperparameters. Below some examples:
- For tree models, it's easy to overfit if the
model_depthparameter isn't set. Then, the model keeps growing until all leaves are pure or until the leave contains less thanmin_samples_splitsamples. You can try different values with hyperparameter tuning to discover the best depth. - In XGBoost, many parameters are related to overfitting. Here are some of them:
colsample_bytreecontains the ratio of features used in the tree, when you use less features you reduce the overfitting effect. Another parameter closely related issubsample, where you specify the ratio of samples used. Setting the learning rateetato a lower number helps too. Andgammais used to control the minimum loss reduction needed for a split. - In logistic regression and support vector machines, the
Cparameter controls the amount of regularization. The strength of the regularization is inversely proportional toC. Or: the higher you set it, the lower the amount of regularization. (This is actually not completely implicit, because it's related to the regularization term.) - In neural networks, the number of layers and the number of neurons per layer can cause overfitting. You can remove layers and neurons to decrease the complexity of the model.
There are many more parameters for different models, you can search online or read documentation to discover them and improve your model.
Dropout regularization
Dropout Regularization is applied during the training of deep neural networks. It randomly drops out a certain number of neurons from the network during each iteration of training, forcing the network to rely on multiple subsets of the neurons and therefore reduce overfitting.

Early stopping
This is a type of regularization that is used to prevent overfitting by monitoring the performance of the model on a validation set and stopping the training when the performance starts to degrade. Some models have Early Stopping built in. XGBoost offers a parameter early_stopping_rounds, and here is how to do it with Keras.

Data augmentation
This is a technique used to prevent Overfitting by artificially enlarging the size of the training data by applying random but realistic transformations to the existing data. Data augmentation is often applied to image data: below you can see some different augmentation techniques (mirroring, cropping and adding effects). There are more, like adjusting lighting, blurring, shifting the subject, etcetera.

Conclusion
This post gives you an explanation and overview of Regularization techniques. Preventing overfitting is an important part when using machine learning models and you have to make sure you handle it in the right way. Besides the techniques from this post, it can help to use cross validation or take care of outliers to reduce the generalization error.
Related
Are You Using Feature Distributions to Detect Outliers?
Model-Agnostic Methods for Interpreting any Machine Learning Model
