Group Equivariant Self-Attention
In the dynamic landscape of growing neural architectures, efficiency is paramount. Tailoring networks for specific tasks involves infusing a priori knowledge, achieved through strategic architectural adjustments. This goes beyond parameter tweaking – it's about embedding a desired understanding into the model. One way of doing this is by using geometric priors – the very topic of this article.

Prerequisites
In a former post we delved into the self-attention operation for vision. Now let's build up on that and extend it by using recent advancements of geometric Deep Learning.
If you are not yet familiar with geometric deep learning, Michael Bronstein created a great introductory series.
The Benefits of Group Equivariant Models
Equivariant models can tailor the search space to the task at hand and reduce the probability of a model to learn spurious relations.

Take a look at this cancer cell for instance. If we take the model to be rotation equivariant, the representation that the model has of this cell image does only rotate with the image but it keeps its structure intact. While if there is no such equivariance, the models representation changes almost arbitrary and thus what looks like a cancer cell at one orientation might look like something completely different when rotated. Clearly, this is not what we want for the task of detecting a certain cell type. We really want to have an equivariant model that understands this rotational symmetry and thus is not affected by rotations or possibly other transformations of the input.
The Blueprint of Geometric Models
When integrating geometric priors into deep learning architectures, a common approach involves a systematic sequence of steps. Initially, the network's layers are expanded to align with the targeted geometric group, such as rotations, resulting in what we term G-equivariant layers. This adaptation ensures that the network captures and respects the specific geometric characteristics inherent in the data.
Throughout this process, local pooling techniques can be strategically applied to manage and streamline network complexity, particularly if a reduction in size is deemed beneficial. The introduction of pooling operations helps focus on essential features while maintaining the network's ability to discern geometric nuances.
Ultimately, the architecture is designed to exhibit invariance under transformations of the chosen geometric group. To achieve this, a global pooling operation over the group dimension is executed in the very end. This step ensures that the network's learned representations remain consistent and reliable, irrespective of the applied geometric transformations.
In essence, this methodology revolves around tailoring the inner workings of the network to accommodate distinct geometric traits, employing pooling strategies for complexity control, and culminating in a network that upholds invariance when subjected to transformations within the specified geometric group.

Group Equivariant Convolutional Neural Networks (G-CNNs)
G-CNNs made their debut in 2016, marking a significant advancement in the realm of neural network architectures. The idea is to apply group transformations on the convolutional kernel of the CNN. Basically, making up two operations called lifting and group convolution.
The concept of lifting convolution involves taking an image and elevating it to the dimension of the chosen group. Let's break it down further using the example of a group with 90-degree rotations.
Here's how it works: imagine our group consists of rotations, and we want to lift a kernel to this group's dimension. We achieve this by rotating the kernel four times, corresponding to the four distinct orientations within the 90-degree rotation group.
Subsequently, we apply these four lifted kernels to the same image. The result are four transformed images, each corresponding to one of the rotated versions of the kernel. This process effectively captures the essence of the group's transformations within the convolutional operation, allowing the network to understand and learn from different orientations of the input data.

After this lifting convolution, we now have a group of four convoluted images. If we want to apply further convolutions, we have to act on the all of the four transformations, instead of only a single input image. For this we use layers of group convolution.

As you can see, we also take the sum over the group dimension, so we keep the dimension constant. In the end, we do a global pooling making our convolution operation invariant under the group action.
Group Equivariant Transformer
With the concept of group equivariant convolution in mind, we can now transfer the same intuition to build group equivariant self-attention. As of this point in time, many deep learning architectures already have a group-equivariant counterpart.
More recently, this is also the case for the transformer model and more specifically, for the self-attention operation that is the engine of the transformer model.
In its initial form, self-attention, lacking positional information, exhibits permutation equivariance. In simpler terms, permuting the input leads to a corresponding permutation of the output. This intrinsic property proves highly versatile, effortlessly accommodating rotations, translations, flips, and other symmetry-preserving actions as special cases of permutations. However, this broad equivariance, while powerful, often proves too general for many tasks, especially when a nuanced sense of position is crucial.
To address this limitation, it has become standard practice to introduce positional information into the model. Intriguingly, when absolute positional information is incorporated, the model forfeits its equivariance properties. This occurs because each input at every position becomes unique, disrupting the desired symmetry. Conversely, leveraging relative positions restores translation equivariance, as the relative orientation remains constant when the positions are shifted.

So what we want is something that encapsulates certain symmetry groups such as rotations, but without being too general, and that is called unique group equivariance. And you can already guess, that we can achieve this by altering the positional information in specific ways using group actions. Turns out, if we think of the absolute positional encoding as a 2D grid, there are many analogies to G-CNNs.
Indeed we can apply the same group transformations to this 2D grid of positions, that we also apply to the 2D convolutional kernel.

Instead of creating for acted versions of the kernel like for G-CNNs we now create for acted versions of the 2D grid of absolute positional indices. We call this operation lifting self-attention.
Then we apply four separate multi-head self-attention operations which gives us four unique representations of the same input image.
Now you can hopefully see how similar the steps are to the group convolution. And we proceed in a similar fashion. We define an operation that we call group self-attention, that directly acts on the lifted version of our indices.

Observe that the group self-attention causes a 90-degree rotation of the kernels and a cyclic permutation along the group axis.
After multiple of such group self-attention layers we do a pooling operation like mean pooling, and thus we create invariance under the group action. We now build a self-attention operation that is invariant under 90-degree rotations of our input. Great!
Now, let's examine the equivariance properties in the context of lifting self-attention and group self-attention. To assess this, we input an image along with its 90-degree rotated counterpart into our network, observing how the model's representation evolves after the lifting and group self-attention operations.
By scrutinizing the changes in the model's representation, we gain insights into the efficacy of the equivariant design. Specifically, we seek to understand how the network responds to variations in the input, especially in terms of rotation. This comparative analysis provides a nuanced perspective on the model's ability to maintain consistent and interpretable (invariant) representations despite transformations in the input data.
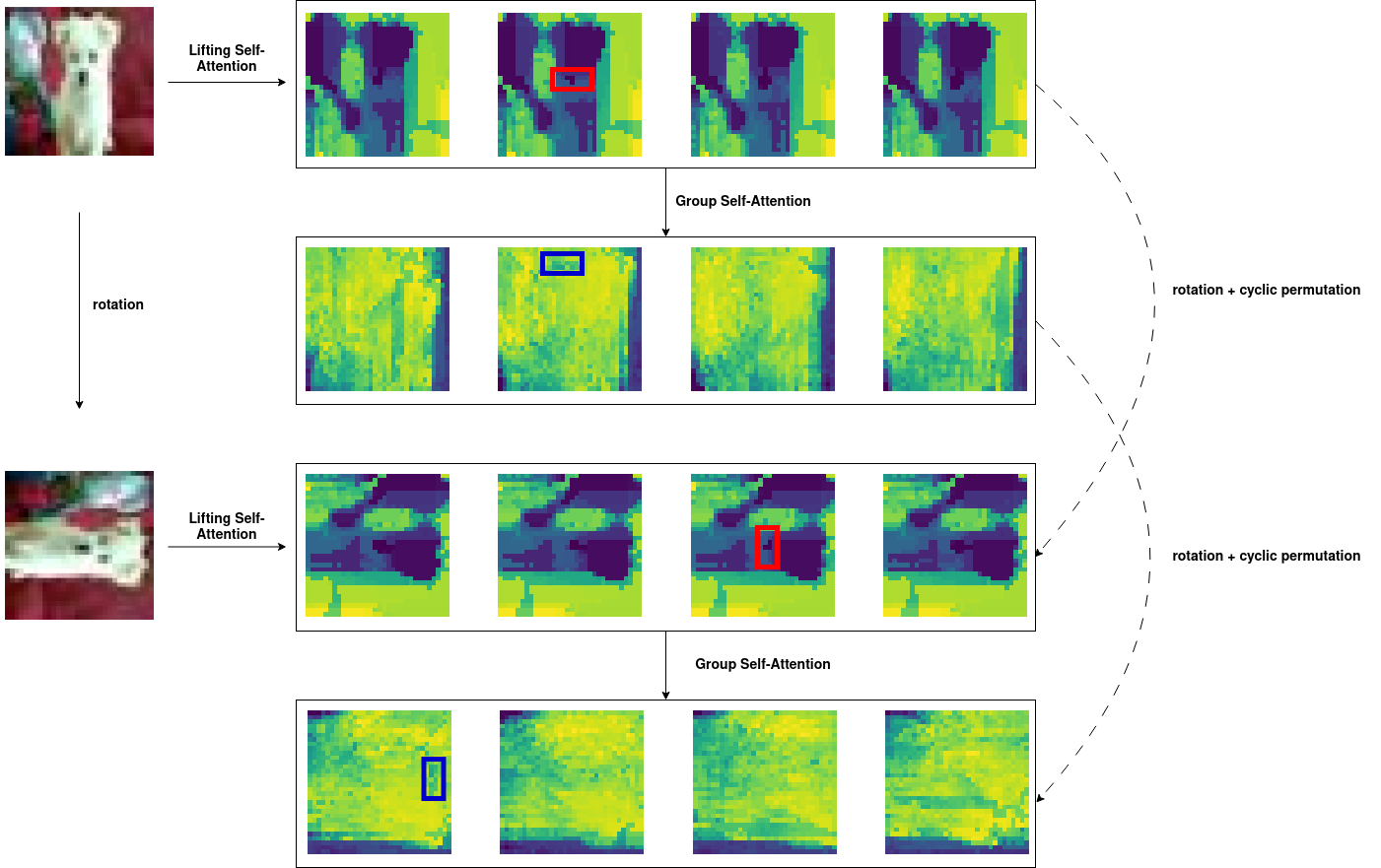
Notably, we observe that the network's representations remain invariant up to a 90-degree rotation and a cyclic permutation. This robust consistency in the model's responses underscores the achieved equivariance, affirming its capacity to preserve essential features and patterns under the group action.
Conclusions
The discovered insights underscore the promising potential of group equivariant priors. The demonstrated capability to sustain consistent representations amidst specific transformations implies a valuable avenue for improving overall network performance and generalization. The integration of group equivariance into the network architecture offers the prospect of heightened stability and generalization, rendering it a compelling approach for applications where geometric patterns in the data can be leveraged.
