Implement interpretable neural models in PyTorch!
TL;DR – Experience the power of interpretability with "PyTorch, Explain!" – a Python library that empowers you to implement state-of-the-art and interpretable concept-based models! [GitHub]

Tutorials inspired by methods presented in:
- ICML 2020 paper "Concept Bottleneck Models";
- NeurIPS 2022 paper "Concept Embedding Models: Beyond the accuracy-explainability trade-off";
- ICML 2023 paper "Interpretable Neural-Symbolic Concept Reasoning".
Motivation
The lack of interpretability in deep learning systems poses a significant challenge to establishing human trust. The complexity of these models makes it nearly impossible for humans to understand the underlying reasons behind their decisions.
The lack of interpretability in deep learning systems hinders human trust.
To address this issue, researchers have been actively investigating novel solutions, leading to significant innovations such as concept-based models. These models not only enhance model transparency but also foster a renewed sense of trust in the system's decision-making by incorporating high-level human-interpretable concepts (like "colour" or "shape") in the training process. As a result, these models can provide simple and intuitive explanations for their predictions in terms of the learnt concepts, allowing humans to check the reasoning behind their decisions. And that's not all! They even allow humans to interact with the learnt concepts, giving us control over the final decisions.
Concept-based models allow humans to check the reasoning behind deep learning predictions and give us back control over the final decision.
In this blog post, we will delve into these techniques and provide you with the tools to implement state-of-the-art concept-based models using simple PyTorch interfaces. Through hands-on experience, you will learn how to leverage these powerful models to enhance interpretability and ultimately calibrate human trust in your deep learning systems.
Tutorial #1: Implement your first concept bottleneck model
To showcase the power of PyTorch Explain, let's dive into our first tutorial!
A primer on concept bottleneck models
In this introductory session, we'll dive into concept bottleneck models. These models, introduced in a paper [1] presented at the International Conference on Machine Learning in 2020, are designed to first learn and predict a set of concepts, such as "colour" or "shape," and then utilize these concepts to solve a downstream classification task:

By following this approach, we can trace predictions back to concepts providing explanations like "The input object is an {apple} because it is {spherical} and {red}."
Concept bottleneck models first learn a set of concepts, such as "colour" or "shape," and then utilize these concepts to solve a downstream classification task.
Hands-on concept bottlenecks
To illustrate concept bottleneck models, we will revisit the well-known XOR problem, but with a twist. Our input will consist of two continuous features. To capture the essence of these features, we will employ a concept encoder that maps them into two meaningful concepts, denoted as "A" and "B". The objective of our task is to predict the exclusive OR (XOR) of "A" and "B". By working through this example, you'll gain a better understanding of how concept bottlenecks can be applied in practice and witness their effectiveness in tackling a concrete problem.
We can start by importing the necessary libraries and loading this simple dataset:
import torch
import torch_explain as te
from torch_explain import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
x, c, y = datasets.xor(500)
x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)Next, we instantiate a concept encoder to map the input features to the concept space and a task predictor to map concepts to task predictions:
concept_encoder = torch.nn.Sequential(
torch.nn.Linear(x.shape[1], 10),
torch.nn.LeakyReLU(),
torch.nn.Linear(10, 8),
torch.nn.LeakyReLU(),
torch.nn.Linear(8, c.shape[1]),
torch.nn.Sigmoid(),
)
task_predictor = torch.nn.Sequential(
torch.nn.Linear(c.shape[1], 8),
torch.nn.LeakyReLU(),
torch.nn.Linear(8, 1),
)
model = torch.nn.Sequential(concept_encoder, task_predictor)We then train the network by optimizing the cross-entropy loss on both concepts and tasks:
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01)
loss_form_c = torch.nn.BCELoss()
loss_form_y = torch.nn.BCEWithLogitsLoss()
model.train()
for epoch in range(2001):
optimizer.zero_grad()
# generate concept and task predictions
c_pred = concept_encoder(x_train)
y_pred = task_predictor(c_pred)
# update loss
concept_loss = loss_form_c(c_pred, c_train)
task_loss = loss_form_y(y_pred, y_train)
loss = concept_loss + 0.2*task_loss
loss.backward()
optimizer.step()After training the model, we evaluate its performance on the test set:
c_pred = concept_encoder(x_test)
y_pred = task_predictor(c_pred)
concept_accuracy = accuracy_score(c_test, c_pred > 0.5)
task_accuracy = accuracy_score(y_test, y_pred > 0)Now, after just a few epochs, we can observe that both the concept and the task accuracy are quite good on the test set (~98% accuracy)!
Thanks to this architecture we can provide explanations for a model prediction by looking at the response of the task predictor in terms of the input concepts, as follows:
c_different = torch.FloatTensor([0, 1])
print(f"f({c_different}) = {int(task_predictor(c_different).item() > 0)}")
c_equal = torch.FloatTensor([1, 1])
print(f"f({c_different}) = {int(task_predictor(c_different).item() > 0)}")which yields e.g., f([0,1])=1 and f([1,1])=0 , as expected. This allows us to understand a bit more about the behaviour of the model and check that it behaves as expected for any relevant set of concepts e.g., for mutually exclusive input concepts [0,1]or [1,0] it returns a prediction of y=1.
Concept bottleneck models provide intuitive explanations by tracing predictions back to concepts.
Drowning in the accuracy-explainability trade-off
One of the key advantages of concept bottleneck models is their ability to provide explanations for their predictions by revealing concept-prediction patterns allowing humans to assess whether the model's reasoning aligns with their expectations.
However, the main issue with standard concept bottleneck models is that they struggle in solving complex problems! More generally, they suffer from a well-known issue in Explainable Ai, referred to as the accuracy-explainability trade-off. Practically, we desire models that not only achieve high task performance but also offer high-quality explanations. Unfortunately, in many cases, as we strive for higher accuracy, the explanations provided by the models tend to deteriorate in quality and faithfulness, and vice versa.
Visually, this trade-off can be represented as follows:

where interpretable models excel at providing high-quality explanations but struggle with solving challenging tasks, while black-box models achieve high task accuracy at the expense of providing brittle and poor explanations.
To illustrate this trade-off in a concrete setting, let's consider a concept bottleneck model applied to a slightly more demanding benchmark, the "trigonometry" dataset:
x, c, y = datasets.trigonometry(500)
x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)Upon training the same network architecture on this dataset, we observe significantly diminished task accuracy, reaching only around 80%.
Concept bottleneck models fail to strike a balance between task accuracy and explanation quality.
This begs the question: are we perpetually forced to choose between accuracy and the quality of explanations, or is there a way to strike a better balance?
Tutorial #2: Beyond the accuracy-explainability trade-off with concept embedding models
The answer is "yes!", a solution does exist!
A primer on concept embedding models
A recent solution to address this challenge was introduced at the Advances in Neural Information Processing Systems conference in a paper called "Concept Embedding Models: Beyond the accuracy-explainability trade-off" [2] (I discuss this method more extensively in this blog post if you want to know more!). The key innovation of this paper was to design supervised high-dimensional concept representations. Unlike standard concept bottleneck models that represent each concept with a single neuron's activation:

… a concept embedding model represents each concept with a set of neurons, effectively overcoming the information bottleneck associated with the concept layer:

As a result, concept embedding models enable us to achieve both high accuracy and high-quality explanations simultaneously:

Concept embedding models succeed in striking a balance between task accuracy and explanation quality.
Hands-on concept embedding models
Implementing these models in Pytorch is as easy as it was with standard concept bottleneck models!
We start by loading our data:
x, c, y = datasets.trigonometry(500)
x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)Next, we instantiate a concept encoder to map the input features to the concept space and a task predictor to map concepts to task predictions:
embedding_size = 8
concept_encoder = torch.nn.Sequential(
torch.nn.Linear(x.shape[1], 10),
torch.nn.LeakyReLU(),
te.nn.ConceptEmbedding(10, c.shape[1], embedding_size),
)
task_predictor = torch.nn.Sequential(
torch.nn.Linear(c.shape[1]*embedding_size, 8),
torch.nn.LeakyReLU(),
torch.nn.Linear(8, 1),
)
model = torch.nn.Sequential(concept_encoder, task_predictor)We then train the network by optimizing the cross-entropy loss on both concepts and tasks:
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01)
loss_form_c = torch.nn.BCELoss()
loss_form_y = torch.nn.BCEWithLogitsLoss()
model.train()
for epoch in range(2001):
optimizer.zero_grad()
# generate concept and task predictions
c_emb, c_pred = concept_encoder(x_train)
y_pred = task_predictor(c_emb.reshape(len(c_emb), -1))
# compute loss
concept_loss = loss_form_c(c_pred, c_train)
task_loss = loss_form_y(y_pred, y_train)
loss = concept_loss + 0.2*task_loss
loss.backward()
optimizer.step()After training the model, we evaluate its performance on the test set:
c_emb, c_pred = concept_encoder.forward(x_test)
y_pred = task_predictor(c_emb.reshape(len(c_emb), -1))
concept_accuracy = accuracy_score(c_test, c_pred > 0.5)
task_accuracy = accuracy_score(y_test, y_pred > 0)Now, after just a few epochs, we can observe that both the concept and the task accuracy are quite good on the test set (~96% accuracy), almost ~15% higher than with a standard concept bottleneck model!
Why interpretability > explainability?
Despite the simplicity and intuitiveness of the explanations provided by the techniques discussed thus far, there is still an inherent limitation: the precise logical reasoning behind the model's predictions remains unclear.
In fact, even if we were to employ a transparent machine learning model like a decision tree or logistic regression, it wouldn't necessarily alleviate the issue when using concept embeddings. This is because the individual dimensions of concept vectors lack a clear semantic interpretation for humans. For instance, a logic sentence in a decision tree stating"if {yellow[2]>0.3} and {yellow[3]<-1.9} and {round[1]>4.2} then {banana}" does not hold much semantic meaning as terms like "{yellow[2]>0.3}" (referring to the second dimension of the concept vector "yellow" being greater than "0.3") do not carry significant relevance to us.

Even transparent models cannot provide interpretable predictions when applied on concept embeddings.
How can we overcome this challenge this time?!
Step #3: Interpretability without compromises
Again, a solution does exist!
A primer on deep concept reasoning
Deep Concept Reasoners [3] (a recent paper accepted at the 2023 International Conference on Machine Learning) address the limitations of concept embedding models by achieving full interpretability using concept embeddings. The key innovation of this method was to design a task predictor which processes concept embeddings and concept truth degrees separately. While a standard machine learning model would process concept embeddings and concept truth degrees simultaneously:
a deep concept reasoner generates (interpretable!) logic rules using concept embeddings and then executes rules symbolically assigning to concept symbols their corresponding truth value:
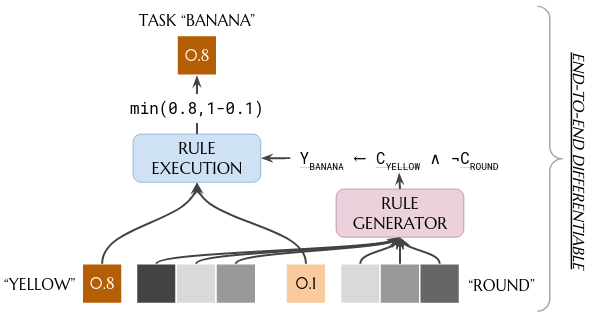
Deep concept reasoners provide interpretable predictions when applied on concept embeddings as each prediction is generated using a logic rule of concept truth degrees.
This unique technique allows us to implement models that are perfectly interpretable, as they make predictions based on logic rules as a decision tree! What sets them apart is their remarkable performance on challenging tasks, surpassing that of traditional interpretable models like decision trees or logistic regression:

By leveraging deep concept reasoning, we can unlock the potential for highly interpretable models that offer superior performance on complex tasks.
Deep concept reasoners provide interpretable predictions while outperforming interpretable models in terms of task accuracy.
Hands-on deep concept reasoning
Implementing deep concept reasoning is again quite easy using the pytorch_explain library!
As in previous examples, we instantiate a concept encoder to map the input features to the concept space and a deep concept reasoner to map concepts to task predictions:
from torch_explain.nn.concepts import ConceptReasoningLayer
import torch.nn.functional as F
x, c, y = datasets.xor(500)
x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)
y_train = F.one_hot(y_train.long().ravel()).float()
y_test = F.one_hot(y_test.long().ravel()).float()
embedding_size = 8
concept_encoder = torch.nn.Sequential(
torch.nn.Linear(x.shape[1], 10),
torch.nn.LeakyReLU(),
te.nn.ConceptEmbedding(10, c.shape[1], embedding_size),
)
task_predictor = ConceptReasoningLayer(embedding_size, y_train.shape[1])
model = torch.nn.Sequential(concept_encoder, task_predictor)We then train the network by optimizing the cross-entropy loss on both concepts and tasks:
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01)
loss_form = torch.nn.BCELoss()
model.train()
for epoch in range(2001):
optimizer.zero_grad()
# generate concept and task predictions
c_emb, c_pred = concept_encoder(x_train)
y_pred = task_predictor(c_emb, c_pred)
# compute loss
concept_loss = loss_form(c_pred, c_train)
task_loss = loss_form(y_pred, y_train)
loss = concept_loss + 0.2*task_loss
loss.backward()
optimizer.step()After training the model, we can evaluate its performance on the test set and check that it matches the accuracy of a concept embedding model (~99%):
c_emb, c_pred = concept_encoder.forward(x_test)
y_pred = task_predictor(c_emb, c_pred)
concept_accuracy = accuracy_score(c_test, c_pred > 0.5)
task_accuracy = accuracy_score(y_test, y_pred > 0.5)However, this time we can get the precise and exact reasoning behind each prediction by reading the corresponding logical rule:
local_explanations = task_predictor.explain(c_emb, c_pred, 'local')where each element in local_explanations has the following structure:
{'sample-id': 0,
'class': 'y_1',
'explanation': '~c_0 & c_1',
'attention': [-1.0, 1.0]}Similarly, we can extract global explanations using the command:
global_explanations = task_predictor.explain(c_emb, c_pred, 'global')which returns the full set of rules found by the model, enabling humans to double check that the reasoning of the deep learning system matches the expected behaviour:
[{'class': 'y_0', 'explanation': 'c_0 & c_1', 'count': 39},
{'class': 'y_0', 'explanation': '~c_0 & ~c_1', 'count': 46},
{'class': 'y_1', 'explanation': '~c_0 & c_1', 'count': 45},
{'class': 'y_1', 'explanation': 'c_0 & ~c_1', 'count': 35}]Key takeaways
In this post, we have explored the key features of the pytorch_explain library, highlighting state-of-the-art concept-based architectures and demonstrating their implementation with just a few lines of code.
Here's a recap of what we covered:
- Concept bottleneck models: These models provide intuitive explanations by tracing predictions back to a set of human-interpretable concepts;
- Concept embedding models: By overcoming the information bottleneck associated with concepts, these models achieve high prediction accuracy without compromising the quality of explanations;
- Deep concept reasoners: The predictions of these models are fully interpretable as deep concept reasoners make predictions using logical rules composing concepts' truth values.
By utilizing the powerful capabilities of the "Pytorch, Explain!" library and implementing the techniques discussed, you have the opportunity to significantly enhance the interpretability of your models while maintaining high prediction accuracy. This not only empowers you to gain deeper insights into the reasoning behind model predictions but also fosters and calibrates users' trust in the system.
References
[1] Koh, Pang Wei, et al. "Concept bottleneck models." International Conference on Machine Learning. PMLR, 2020.
[2] Zarlenga, Mateo Espinosa, et al. "Concept embedding models: Beyond the accuracy-explainability trade-off." Advances in Neural Information Processing Systems. Vol. 35. Curran Associates, Inc., 2022. 21400–21413.
[3] Barbiero, Pietro, et al. "Interpretable Neural-Symbolic Concept Reasoning." arXiv preprint arXiv:2304.14068 (2023).
