Understanding Junctions (Chains, Forks and Colliders) and the Role they Play in Causal Inference

Introduction
Causal Inference is the application of probability, visualisation, and machine learning in understanding the answer to the question "why?"
It is a relatively new field of data science and offers the potential to extend the benefits of predictive algorithms which address the symptoms of an underlying business problem to permanently curing the business problem by establishing cause and effect.
Typically causal inference will start with a dataset (like any other branch of Data Science) and then augment the data with a visual representation of the causes and effects enshrined in the relationships between the data items. A common form of this visualisation is the Directed Acyclic Graph or DAG.
The Problem
DAGs look deceptively simple but they hide a lot of complexity which must be fully understood to maximise the application of causal inference techniques.
The Opportunity
Even the most complex DAGs can be broken down into a collection of junctions which can only be one of 3 patterns – a chain, a fork, or a collider – and once those patterns are explained the more complex techniques can be built up, understood and applied.
The Way Forward
This article will take the time to fully explain and understand the 3 patterns of junction setting the foundations for the reader to understand the detail of complex causal inference techniques.
Background
We are going to need an example DAG to explore and explain. I have constructed the fictitious DAG below because it is sufficiently simple to effectively explore the concepts and sufficiently complex to contain all 3 types of junctions …

This DAG represents the proposed causal relationships found within a dataset that contains 6 features or variables – X, Z1, Z2, Z3, W and Y.
In causal problems we are interested in isolating the effect of a treatment (in this case X) on an outcome (in this case Y) whilst adjusting for the effects of the other variables.
For example in the proposed DAG "Z3" is affecting both the treatment and the outcome and this needs to be accounted and adjusted for in any causal solution.
"Treatment" and "outcome" sound like medical terms and indeed the terminology is borrowed from the medical field as that is where a lot of the work originated.
However it should be noted that causal inference is equally applicable to non-medical domains but by convention the terms "treatment" and "outcome" are used universally.
If you are wondering about the relationship between the DAG and the data, each node in the DAG represents a column in the data and each arrow is showing a proposed causal link i.e. data in feature X influences or causes data in column W to change which in turn causes changes in Y.
The dataset for this DAG can be viewed as follows …

Note: all data used in this article is entirely synthetic and has been created by the author.
The next concept is that there are many paths or routes through the DAG. Paths always start at the treatment, always end at the outcome and are acyclic (i.e. they do not loop back).
Given these concepts can you calculate how many possible paths exist in the example DAG?
The answer is 5 which can be visualised as follows …

It is also common to see paths represented in a flattened, textual form which can be confusing at first but once explained they are very straightforward. The 5 paths visualised above can be expressed in this form as follows …
1) X -> W -> Y
2) X <- Z1 -> Z3 -> Y
3) X <- Z1 -> Z3 <- Z2 -> Y
4) X <- Z3 -> Y
5) X <- Z3 <- Z2 -> YThe next step in understanding even the most complex DAGs is the concept of junctions. All DAGs and all paths within them are made up of junctions where each junction has exactly 3 nodes and 2 connections.
For example our first path (X -> W -> Y) is also a junction because it has exactly 3 nodes and exactly 2 connections.
Path 2 (X <- Z1 -> Z3 -> Y) is slightly more complicated; it contains 2 junctions –
- X <- Z1 -> Z3
- Z1 -> Z3 -> Y
Path 3 (X <- Z1 -> Z3 <- Z2 -> Y) contains 3 junctions –
- X <- Z1 -> Z3
- Z1 -> Z3 <- Z2
- Z3 <- Z2 -> Y
It is easy to understand the relationship between DAGs, paths and junctions by simply visualising all junctions in the example DAG …

1) X -> W -> Y
2) Z1 -> X -> W
3) Z3 -> X -> W
4) Z1 -> Z3 -> X
5) Z1 -> Z3 -> Y
6) Z2 -> Z3 -> X
7) Z2 -> Z3 -> Y
8) X <- Z1 -> Z3
9) X <- Z3 -> Y
10) Y <- Z2 -> Z3
11) W -> Y <- Z2
12) W -> Y <- Z3
13) Z2 -> Y <- Z3
14) Z1 -> X <- Z3
15) Z1 -> Z3 <- Z2It should be apparent from a quick review of all junctions within our DAG that there are just 3 possible patterns or types.
Junction 1 (X -> W -> Y) is an example of a "chain" where the first node points to the intermediary (X -> W) and the intermediary "points" to the final node (W -> Y).
Junction 8 (X <- Z1 -> Z3) is an example of a "fork" where the intermediary node points to both the first node (X <- Z1) and the final node (Z1 -> X).
Junction 11 (W -> Y <- Z2) is an example of a "collider" where the first node points to the intermediary (W -> Y) and the final node also points to the intermediary (Y <- Z2).
It turns out that an understanding of these 3 patterns is critical to understanding many of the concepts of causal inference.
For example causal validation is the process of validating the DAG against the dataset, i.e. establishing if the proposed DAG is likely to be an accurate representation of the causal relationships that exist in the data, and the different behaviour of chains, forks and colliders is fundamental to understanding and implementing this validation.
The remainder of this article is dedicated to exploring chains, forks and colliders in more detail but before we get started let's take a short detour …
Detour 1: What Came First – The Chicken (The Data) or the Egg (The Directed Acyclic Graph)?

One aspect that could be better explained in the available literature is the relationship between the dataset and the Directed Acyclic Graph and because it is usually the opposite way round in real life problems to theoretical problems it can be confusing to understand.
Real-world causal inference problems are just an extension of more traditional Machine Learning problems (like classification or regression) but in causal inference we are interested in not just predicting what may happen but understanding why it happened in the first place.
Causal inference problems therefore always start with a dataset, just like any other machine learning project. In order to answer the "why?" type problems the dataset must be associated with a Directed Acyclic Graph that captures and visualises the causal relationships that exist in the data and the DAG is usually created through an iterative refinement process involving data scientists asking the right questions and domain experts answering using their expertise.
At some stage a refinement of the DAG will have been produced that all parties are happy with and then the process of solving causal inference problems begins.
It should also be noted that some automation can be brought to bear in the process of creating a DAG from a dataset. Causal Discovery is the concept of automatically generating a DAG from the data and Causal Validation is the process of testing a proposed DAG against a dataset. It is typically possible for more than one DAG to satisfy the causal validation tests against a given dataset, hence these approaches are complex and uncertain. I will return to these concepts in future articles but it is worth having an awareness of them as part of this explanation.
In theoretical causal inference problems (like the ones in this article) the exact opposite is the case. This type of problem typically starts by selecting or designing a DAG to best illustrate the points, for example the 6 node DAG selected at the start of the article.
So where does the data come from in theoretical causal inference problems when the DAG comes first? In these instances a synthetic, artificial dataset will be generated that matches the DAG and it turns out this can be done very easily by following these steps …
- Start with the fictitious / test DAG that requires an associated dataset …
- Attach a weighting to each arrow on the DAG (the weightings can be selected at random)…

- Create a "structural equation" for each node by considering all of the incoming arrows and their associated weightings …
Z1 = np.random.normal(4.753198042323167, 1.720324493442158)
Z2 = np.random.normal(3.289942920829799, 1.8849665188380633)
Z3 = 3 x Z1 + -1.5 x Z2 + ε
X = 2 x Z1 + 2.5 x Z3 + ε
W = 3 x X + ε
Y = 2 x W + 2 x Z2 + -3 x Z3 + εTo complete the explanation all that is required is to understand the distinction between exogenous nodes and endogenous nodes. Exogenous nodes have no incoming causal arrows so in the example DAG the exogenous nodes are Z1 and Z2 and the endogenous nodes are X, W, Y and Z3. Exogenous variables must be assigned values randomly, usually by following a rule on a distribution.
The 6 structural equations (one for each node on the DAG) can therefore be fully explained and understood as follows ..
- Z1 is an exogenous variable (i.e. it has no inputs) that is normally distributed with a mean of 4.75 and a standard deviation of 1.82
- Z2 is an exogenous variable that is normally distributed with a mean of 3.29 and a standard deviation of 1.88
- Z3 = 3 x Z1–1.5 x Z2 + an error term
- X = 2 x Z1 + 2.5 x Z3 + an error term
- W = 3 x X + an error term
- Y = 2 x W + 2 x Z2 – 3 x Z3 + an error term
- Generate the Data
Armed with this understanding it is very straightforward to write a few lines of Python to generate a dataset that exactly matches the test DAG where the causal relationships are described by the structural equations …
Note that if np.random.seed(seed=...) is set the same data set will be generated each time the code is run, however if it is not set the dataset will be different each time (though each dataset generated will still be described by the structural equations and will match the DAG).
Once examples have been provided and worked through it is easy to understand the difference between real-world problems where the data has been collected first and the DAG developed by experts second, and theoretical / example problems where the test DAG is created first and then the test data engineered to match the DAG afterwards.
However this explanation is often skipped in many of the available texts books and online articles which will lead to a lack of understanding of everything that follows.
Now this detour is complete, let's progress to an in-depth exploration of chains, forks and colliders.
Chains
Let's start by reviewing a visualisation of a chain …

The "chain" is the most straightforward pattern for a junction and is easy to understand. In our example X is the treatment, Y is the outcome and Z is the intermediary.
To provide an example X could be representing the amount of a drug that was taken in a trial, Z could represent the affect the drug had on the patients blood pressure and Y the change in patient outcome.
In the literature we are told that in a chain messages can pass from X to Y but when I first read the literature I did not understand what this meant. There was no explanation of what a message was or how it might be passed from the treatment to the outcome.
Put simply the definition of message passing is that if the value of variable X changes then the value of Y is changed and whilst this can be a difficult concept there are 4 different ways to visualise this definition which when considered together provide a comprehensive explanation.
1. Using Maths
In our example Z = 2 x X and Y = -1.5 x Z and these two equations can be solved using substitution as follows –

This also makes intuitive sense from the DAG above because the 2 weightings on the arrows are just multiplied together to reveal the full effect of changing X on Y.
The maths can also be validated by creating a calculated column in the data by multiplying X by -3. The calculated column can then be compared to the value for Y noting that the structural equations include error terms so the calculated column should be close to the value of Y but will never be an exact match …

2. Using Correlation
If there is an association between X and Y then this should be clearly visible if we plot the data points for X on the X axis against the data points for Y on the Y axis and also the line that best fits those datapoints should have a co-efficient that matches our calculated value for the effect of X on Y …

The scatter chart of X vs. Y confirms the maths and the co-efficient of the line is -2.97 which is very close to the result from the maths of -3 noting again that the presence of error terms in the structural equations that were used to generate the data mean they will never match exactly.
3. Using Dependence
In a recent article I explained and explored the concept of dependence and why it is important in causal inference and causal validation –
Demystifying Dependence and Why it is Important in Causal Inference and Causal Validation
That understanding leads to another notation for expressing the relationship between X and Y in the chain junction …

… which can be read as "Y is dependent on X" (the ⫫̸ symbol is a "slashed double up-tack" and is used to represent dependence).
True4. Using Regression
The final method of highlighting the relationship between between X and Y is to perform an Ordinary Least Squares (OLS) regression and to see if the relationship exists in the summary.
To implement this for our chain it is a simple matter of regressing on Y ~ X using the following Python code …

Once again the result has been validated. The OLS calculated co-efficient of X on Y is -2.9658 which is very close to the -2.97 shown on the correlation and -3 which was calculated using the mathematical method.
Detour 2: The Effect of Conditioning on Z

Before we progress from chains to forks it is worth spending some time exploring the concept of conditioning and the role it plays in DAGs in causal inference.
The literature states that conditioning on the intermediary of a chain junction stops the flow of messages from the treatment to the outcome.
Again I was confused by this statement which is typically made without a detailed explanation in the literature, but as usual a few worked examples can clear the confusion away …
Conditioning in Real-World Trials and Experiments
Outside of the techniques used in causal inference the gold-standard in establishing cause-and-effect relationships is the "Randomized Control Trial" (RCT). For example patients could be randomly allocated into two groups, one receiving a drug and the other a placebo. The theory goes that if the subjects have been selected at random and the "drug" group shows improved outcomes then there is causality.
Here is one potential definition of conditioning …
Conditioning in the context of Randomized Control Trials is the process of assigning participants to different treatment groups, often through randomization or stratification, to ensure unbiased comparisons and control for potential confounding variables.
Beyond group assignment there is also mention of "stratification". Let us assume that we believe that the drug in question has different outcomes for different genders and / or for different ages. In this case the results of the drug trial experiment could be improved by "stratifying" the groups by gender / age (i.e. forming sub-groups based on these attributes) and then averaging the effect across these groups using the numbers of subjects in each.
Let's assume our trial group was split in two for male (60 subjects) and female (40 subjects). The stratified outcome of the drug effect would then be …
0.6× the result for male subjects + 0.4 × the result for female subjects
Conditioning in Causal Inference Models with Binary Data
That is great for RCTs but this type of group division may not be possible in causal models for several reasons. The data obtained may be historical so it could be too late to organise the participants into groups. Also it may be unethical. If our causal problem involved smoking we could not randomly choose groups and instruct them to smoke or not smoke. Lastly it could be logistically impossible to achieve the organisation we want.
However, conditioning can be "simulated" in causal inference models in a way that achieves the same effect using a mathematical formula called the Backdoor Adjustment Formula.
Consider the following DAG …

If we have a set of data for variables X, Y and Z and that data is binary (i.e. 1 = True / Yes and 0 = False / No) then it is possible to condition on Z (which clearly influences both the treatment X and the outcome Y) by applying the following formula to the data …

The left hand side reads ‘what is the probability of Y given that we "do" X‘, for example "what is the probability of recovery=1 given that we do drug=1?"
A full explanation of backdoor adjustment is outside of the scope of this article but if you want to know more check this article out …
Unlock the Power of Causal Inference : A Data Scientist's Guide to Understanding Backdoor…
Conditioning in Causal Inference Models with Continuous Data
Conditioning can also be simulated in causal inference models with continuous data by using a different method.
In the example above the chain X -> Z -> Y was evaluated using Ordinary Least Squares and regressed using this formula Y ~ X. There are several examples in the literature that state that to control for a variable in a causal model with continuous data the variable to be controlled for should simply be included in the regression i.e. Y ~ X should be replaced with Y ~ X, Z.
I have never found a good explanation as to why this works in any of the texts I have studied but I can confirm that it certainly does work by carrying out experiments in Python code and recording the results.
To see this in action let's return to the chain example …

We have already established and explained what it means for messages to travel from X to Y in a chain and we have implemented this in Python noting that …
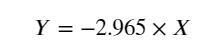
… which is very close to the true result obtained by multiplying the co-efficient rZX by the co-efficient rYZ i.e. …

So if the claims in the various causal inference texts are correct it follows that if we condition on Z (by including it in the regression) then the co-efficient of -2.9658 for the effect of X on Y should disappear simply by including Z in the formula …

By including Z in the regression the co-efficient of X has dropped from -2.9658 to 0.1 (i.e. disappeared) and the p-value has changed from 0.000 (refuting the null hypothesis that no association exists between X and Y) to 0.300 (accepting the null hypothesis that no association exists).
Given the lack of good explanations in the available literature I cannot fully explain why this works but I can verify through many Python experiments that it does work consistently enough to be included in Causal Inference models.
Conditioning in Causal Inference Models: Why Bother?
So what is the point of this detour? Well it transpires that being able to control the flow of messages around a Directed Acyclic Graph is a key concept in causal inference.
Returning to the example above …
… we know that if the data is binary we can apply the backdoor adjustment formula to calculate the de-confounded effect of X on Y but for continuous / non-binary data this approach does not work.
However, now we understand that we can condition for Z by including it in the regression so we have a method that works for continuous data as well.
Understanding the flow of messages around a DAG is critically important in Causal Validation (where a proposed DAG is validated against the data in a real-world problem) and Causal Discovery (where an attempt is made to automatically infer the DAG from the data).
Armed with the knowledge gained in this detour we can now progress beyond chains to explore how messages are passed in forks and colliders …
Forks
As with the chain pattern let's start by visualising a fork junction …
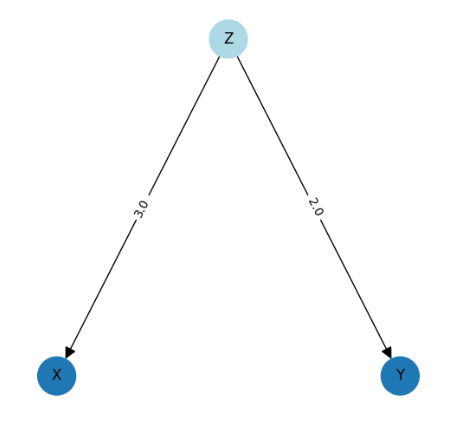
The causal inference literature consistently states that in the chain pattern messages can flow from X (the treatment) to Y (the outcome) and returning to the earlier definition this means that if the value of variable X changes then the value of Y is changed.
This concept is easy to visualise for a chain where the causal arrows points from X to Z and Z to Y but for a long time I could not understand how this can work for a collider because the first causal arrow is pointing from Z to X so how can messages pass from X to Y in a chain junction?
As with most concepts in causal inference, what appears complex can be made simple through worked examples …
1. Using Maths
The key to understanding the mathematical exploration of message passing in forks is to re-consider the relationship between X and Z …

The maths can be validated by creating a calculated column in the data by multiplying X by 2/3. The calculated column can then be compared to the value for Y noting that the structural equations include error terms so the calculated column should be close to the value of Y but will never be an exact match …
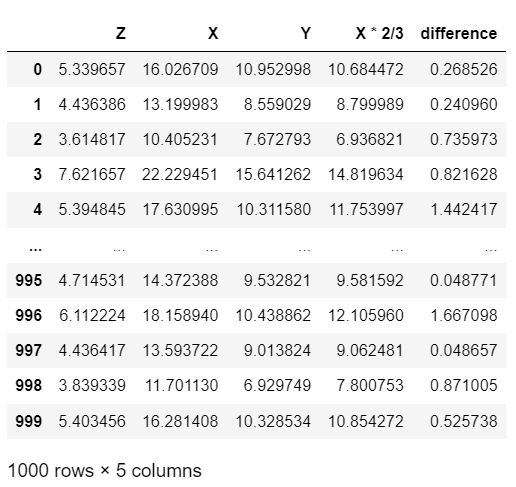
As with the validation test performed for the chain we can see that the difference between the true value of Y (which includes an error term) and the value calculated by multiplying X by 2/3 is very similar thus proving that the maths used to calculate and demonstrate the flow of messages was correct.
2. Using Correlation
Again, if there is an association between X and Y then this should be clearly visible if we plot the data points for X on the X axis against the data points for Y on the Y axis and also the line that best fits those datapoints should have a co-efficient that matches our calculated value for the effect of X on Y …

The scatter chart of X vs. Y confirms the maths and the co-efficient of the line is 0.63 which is very close to the result from the maths of 2/3 or 0.66.
3. Using Dependence
Returning to independence, the same relationship should hold true for X and Y …
… i.e. "Y is dependent on X" meaning that a change in X causes a change in Y and once again the Python extension for dependence referenced above can be used to demonstrate this formula in Python code …
True4. Using Regression
The final visualising is the Ordinary Least Squares (OLS) regression and to see if the relationship exists in the output using the same approach as for the chain example …

We can see from the results that the co-efficient of the line describing the effect of X on Y is 0.6288 which matches the results of the correlation and maths methods.
Concluding Forks
We can see from 4 different methods – maths, correlation, dependence and regression – what it means when the causal literature states that messages can pass from the start to the end node in a fork junction and having 4 different ways of visualising this makes it easy to understand.
A quick closing note on forks. If we condition on the intermediary in a fork junction, then message passing will be blocked in exactly the same way as it is in a chain …
Addressing the Elephant in the Room
One of the stated uses for understanding and influencing junctions is in causal validation where real world data is compared to a proposed DAG to check if the DAG has correctly captured the causality in the data.
However, you may have noticed that in the examples above chains and forks exhibit identical behaviour i.e. messages can pass through the both chains and forks but messages are blocked in both cases when conditioning on the intermediary and we can also see that the dependency tests for chains and forks are identical (Y ⫫̸ X and Y ⫫ X | Z)
That certainly is an elephant in the room – if chains and forks exhibit the same behaviour and pass the same tests then how can all this knowledge be used to validate a DAG as these types of junctions cannot be differentiated?
Enter the "collider" pattern …
Colliders
As with the other two patterns let's start by visualising a collider junction using a DAG …

The Causal Inference literature states that in the collider pattern messages cannot flow from X (the start node) to Y (the end node) and this means that if the value of variable X changes then the value of Y is does not change.
Colliders are harder to understand than the other two patterns so let's start with a real-world example …
Let's assume that we are modelling a sporting and academic college and the causes for students being given a bursary. In this example X represents a students sporting ability, Y represents their academic ability and Z represents the bursary.
It is easier to visualise with this example that sporting ability causes bursary as students who are top sportsmen and sportswomen are awarded the bursary. We can also see that high academic achievement is a also a cause of bursary with academically gifted students being awarded bursaries.
If we change X (sporting ability) Y does not change in relation to that change i.e. it is not the case that better sports ability has a correlation with better academic achievement, rather they are independent and do not affect each other.
1. Using Correlation
For forks the first visualisation is correlation because the maths is more complex and hence will be tackled afterwards …

If X represents sporting ability and Y represents academic ability we can clearly see from the correlation that as sporting ability changes their is a no associated change in academic ability and the slope of the best-fit line is completely flat.
2. Using Maths
At this point we should probably mention that if we condition on the intermediary messages that are passed from X to Y in colliders they are the exact opposite of chains and forks.
By default messages do not pass from the start to the end node in a collider but when conditioning on the intermediary they do.
We can now progress with an attempt to visualise colliders using some maths noting that in the chain and fork the objective has been to simplify the equations to one that starts with "Y = …"

So we have solved the equation for Y but we are left with a term for Z whereas the examples for the chain and fork simplified to an expression for Y in terms of just X.
The maths helps to explain why messages cannot pass from X to Y in a collider junction i.e. the equation cannot be simplified to Y = aX.
It also helps to explain why conditioning on Z (or fixing Z) does enable messages to pass from X to Y. For example let's assume in that Z is conditioned (i.e. fixed) to be 21 and see what happens to the equation …

In summary visualising a collider using mathematical equations clearly shows how messages cannot pass from X to Y (i.e. changing the value of X will not change the value of Y) but by conditioning on the intermediary messages do pass from X to Y.
This conclusion is critical to causal validation and causal discovery because it means that given a dataset and a proposed DAG we can differentiate between colliders and the other two types so if the DAG has proposed a collider incorrectly this can be identified.
3. Using Dependence
For colliders there is a different dependence check …
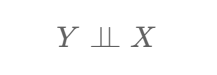
The ⫫ symbol is a "double up-tack" and the formula above can be read as "Y is independent of X".
In fact now we know all about conditioning we can add a second statements as follows …

… which reads as "Y is dependent on X when conditioned on Z"
The Python code below will work if you have adopted the dataframe extensions described in the separate article …
True
True4. Using Regression
Lastly let's take a look at colliders using the regression method …

The co-efficient for X is close to zero (-0.0037) and the p-value is above 0.05 (0.895) accepting the null hypothesis that no association exists between X and Y.
Concluding Colliders

Colliders occur less frequently than chains and forks in real-world causal relationships but they have an important property that makes them extremely useful.
We have already established that in chain and fork junctions messages can pass from the start node to the end node but when conditioning on the intermediary those messages are blocked and this similarity makes it impossible to differentiate chains and forks just by looking at the data.
Colliders exhibit the opposite behaviour. Messages cannot pass from the start to the end node by default but when conditioning on the intermediary the messages are unblocked.
This key difference unlocks significant potential in causal modelling and particularly causal validation. In real-world causal modelling the data will always be the starting point and the DAG will usually have been developed by applying domain expertise which could result in errors and omissions in the DAG.
The implementation of this aspect of causal validation will be for another article but the key principle is that if a collider exists in the data that was omitted in the DAG or a collider was added to the DAG that does not actually exist in the data then it can be detected and the DAG can be corrected!
Conclusion – What Have We Learned?
So what have we learned in this article?
We have learned that causal modelling has the potential for errors where a Directed Acyclic Graph developed using manual, domain expertise does not accurately or completely capture all the causal relationships that exist in the data.
We have learned that a DAG has a node representing each column or feature in the data and a set of unidirectional arrows pointing from one to the other indicating the flow of causality, that there is a single treatment or starting point and a single outcome or end point and that cycles or loops are not allowed.
Each DAG will have a number of paths or routes from the treatment to the outcome and each path is made up of 1 or more junctions, with each junction conforming to one of 3 patterns – a chain, a fork or a collider.
The accepted literature states that messages pass from the start to the end nodes in chains and forks and not in colliders and that the exact opposite is true when conditioning on the intermediary.
Usually the literature offers little or no explanation of the previous statement and this can lead to a fundamental lack of understanding of everything that is built on junctions all the way up to DAGs, causal modelling and causal validation.
In this article the key concept of message passing through junctions has been demystified by considering each junction type in turn and providing 4 different way of looking at and under standing the "passing pf messages" – maths, correlation, dependence and regression.
This article also explained conditioning and how it is nothing more than holding the intermediary constant whilst considering the effect of the treatment on the outcome and then averaging the result for each possible value of the intermediary.
Causal inference is a complex topic but it has the potential to unlock a new wave of data science solutions i.e. moving beyond what is likely to happen (prediction) to why it is likely to happen (causality) and whilst the former enables mitigating action the latter enables the underlying causes to be permanently addressed.
However to unlock that potential data scientists need to learn about a new set of approaches and this article has explained junctions and message passing in detail to aid that journey.
Connect and Get in Touch …
If you enjoyed this article please follow me to keep up to date with future articles.
If you have any thoughts or views, especially on causal inference and where this exciting new branch of data science is going I would love to hear from you – please leave a message and I will get in touch.
My previous articles can be found here – Taking a quick look at my previous articles and this website brings together everything I am doing with my research and causal inference – The Data Blog.
