Data Scaling 101: Standardization and Min-Max Scaling Explained
Data Scaling 101: Standardization and Min-Max Scaling Explained

What is scaling?
When you first load a dataset into your Python script or notebook, and take a look at your numerical features, you'll likely notice that they are all on different scales.
This means that each column or feature will have varying ranges. For example, one feature may have values ranging from 0 to 1, while another can have values ranging from 1000 to 10000.
Take the Wine Quality dataset from UCI Machine Learning Repository (CC by 4.0 License) for example.

Scaling is essentially the process of bringing all the features closer to a similar or same range or scale, such as transforming them so all values are between 0 and 1.
When (and why) you need to scale
There are a few reasons why scaling features before fitting/training a machine learning model is important:
- Ensures that all features contribute equally to the model. When one feature has a large and wide range of numerical values, it may have too high of an impact on the prediction while other smaller features fall to the wayside.
- Performance improvement. Certain algorithms converge faster when features are scaled.
Feature scaling should come after data has been cleaned (nulls removed, outliers removed/imputed, etc), new features have been created through engineering, and a train/test split has been performed. It should be the last step of data preprocessing before a model is fit to the scaled data.
It's important to keep a few things in mind, though, when deciding to scale features:
- Only scale features, not the target variable. It is not necessary to scale the target variable.
- Only scale numerical features. Do not scale categorical features – instead, feed these to the model using one hot encoding or another categorical encoding method.
- Scaling features is only necessary for certain algorithms. Algorithms that use gradient descent to minimize the loss function, such as Linear regression, Logistic regression, and neural networks, are sensitive to difference in feature scales, so scaling is necessary. Distance algorithms such as KNN are also sensitive to scaling. However, tree based algorithms such as Decision Tree and Random Forest are not, so scaling features for these algorithms is not necessary.
Standardization or min-max scaling?
There are two popular methods of scaling features: Standard scaling and min-max scaling.
Standard scaling (also known as standardization) transforms the data so that it has a mean of 0 and a standard deviation of 1. In Python, StandardScaler is used to perform standardization.

Min-max scaling (sometimes referred to as normalization, although the scikit-learn docs do not refer to it as such) transforms the data so that every value falls between 0 and 1. In Python, the MinMaxScaler object is used to perform min max scaling.
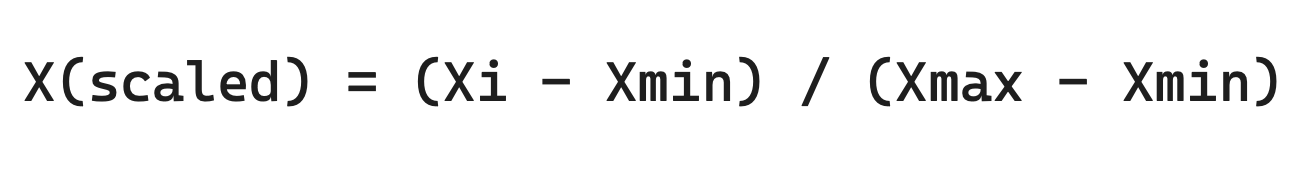
For the most part, either standardization or min-max scaling will do the job when it comes to scaling data before training an ML model. I recommend trying your dataset with both and seeing which (if any) yields better performance.
However, there are some considerations when it comes to selecting one method over the other.
Standardization:
- Results in a distribution with 0 mean and 1 standard deviation
- Many ML algorithms (particularly deep learning algorithms) assume data has a standard normal distribution with 0 mean and unit variance
- Sensitive to outliers
- Better for data which is already normally distributed
Min-Max Scaling:
- Restricts value range to [0,1]
- Sensitive to outliers
- Because it restricts the value range to 0,1, it preserves values of 0 in the case of sparse data
- Preserves original distribution/shape of the data
Implementation
Both scalers are available via the sklearn.preprocessing module, and can be imported as such:
from sklearn.preprocessing import MinMaxScaler, StandardScalerIMPORTANT: Before you scale your data, always be sure to split it into train and test sets first. You do not want to fit your scaler on your entire dataset because this will lead to data leakage.
Your scaler should be fit on your train set only. To fit the scaler to the data and transform the data at the same time, call .fit_transform on the train set. For the test set, you should only call .transform since you don't want to fit or "train" the scaler using the test set.
# First split up X and y into train and test
X_train, X_test,y_train,y_test=train_test_split(X,y)
# Define scaler object - can be MinMaxScaler, StandardScaler, or another
# scaling object
scaler = MinMaxScaler()
# Fit the scaler onto the train set and transform at the same time
X_train = scaler.fit_transform(X_train)
# Only transform on the test set
X_test = scaler.transform(X_test)Now, you have a scaled test and train set that can be used to train your model.
Other scaling methods
Since both StandardScaler and MinMaxScaler are sensitive to outliers, scikit learn offers a helpful alternative: RobustScaler. RobustScaler removes the median and uses the interquartile range (IQR) as a reference point for scaling. IQR is a well known robust method of outlier detection meaning it is not affected by outliers.
For more in depth information on how IQR works, you can check out my article on simple statistical methods and how they are implemented in Python:
The other option is to simply remove or impute outliers prior to fitting a scaler to your data. However if certain methods aren't catching all or most of the outliers in your dataset, RobustScaler could be a safe bet.
Conclusion
Ultimately both StandardScaler and MinMaxScaler are good options for scaling features which have very different ranges, standard deviations and variances. It's beneficial to test out both and see how each one affects the performance of your model.
Starting with StandardScaler as a default could be a good place to start, since many deep learning algorithms assume normality with a mean of 0 and stdev of 1 — as long as your dataset is not highly skewed or abnormal.
This is why it's important to explore your data, check the distribution carefully, and check for outliers before you begin preprocessing.
