Make your sklearn models up to 100 times faster

Introduction
With the Intel® Extension for Scikit-learn package (or sklearnex, for brevity) you can accelerate sklearn models and transformers, keeping full conformance with sklearn's API. Sklearnex is a free software AI accelerator that offers you a way to make sklearn code 10–100 times faster.
The software acceleration is achieved through the use of vector instructions, IA hardware-specific memory optimizations, threading, and optimizations for all upcoming Intel platforms at launch time.
In this story, we'll explain how to use the ATOM library to leverage the speed of sklearnex. ATOM is an open-source Python package designed to help data scientists with the exploration of Machine Learning pipelines. Read this other story if you want a gentle introduction to the library.
Hardware requirements
Additional hardware requirements for sklearnex to take into account:
- The processor must have x86 architecture.
- The processor must support at least one of SSE2, AVX, AVX2, AVX512 instruction sets.
- ARM* architecture is not supported.
- Intel® processors provide better performance than other CPUs.
Note: sklearnex and ATOM are also capable of acceleration through GPU, but we won't discuss that option this story. For now, let's focus on CPU acceleration.
Example
Let's walk you through an example to understand how to get started. We initialize atom the usual way, and specify the engine parameter. The engine parameter stipulates which library to use for the models. The options are:
- sklearn (default)
- sklearnex (our choice for this story)
- cuml (for GPU acceleration)
from atom import ATOMClassifier
from sklearn.datasets import make_classification
# Create a dummy dataset
X, y = make_classification(n_samples=100000, n_features=40)
atom = ATOMClassifier(X, y, engine="sklearnex", n_jobs=1, verbose=2)
Next, call the [run](https://tvdboom.github.io/ATOM/latest/API/ATOM/atomclassifier/#atomclassifier-run) method to train a model. See here a list of models that support sklearnex acceleration.
atom.run(models="RF")
print(f"nThe estimator used is {atom.rf.estimator}")
print(f"The module of the estimator is {atom.rf.estimator.__module__}")
It took 1.7 seconds to train and validate the model. Note how the model is from daal4py. This library is the backend engine for sklearnex.
For comparison purposes, let's train also another Random Forest model, but now on sklearn instead of sklearnex. We can specify the engine parameter also directly on the run method.
atom.run(models="LR_sklearn", engine="sklearn")
print(f"nThe estimator used is {atom.rf.estimator}")
print(f"The module of the estimator is {atom.rf.estimator.__module__}")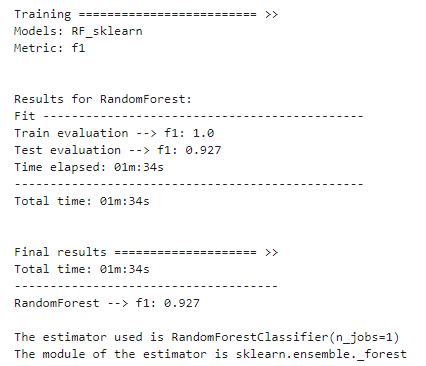
This time it took 1.5 min instead of merely seconds! The former model is almost 60 times faster, and it even performs slightly better on the test set.
Let's visualize the results.
atom.plot_results(metric="time")It's importance to note that there are no big differences between the models, both in terms of performance and in the logic used by the model to make its predictions. The latter statement can be visualized with a feature importance plot (where features have similar importance) and a comparison of shap decision plots (where the decision patterns match).
atom.plot_feature_importance(show=10)atom.rf.plot_shap_decision(show=10, title="sklearnex")
atom.rf_sklearn.plot_shap_decision(show=10, title="sklearn")
Conclusion
We have learned how to easily speed up the training of your sklearn models using the ATOM library. The acceleration is achieved on CPU. How to do this on GPU is the scope of a future story, so stay tuned.
For further information about ATOM, have a look at the package's documentation. For bugs or feature requests, don't hesitate to open an issue on GitHub or send me an email.
Related stories:
- atom-a-python-package-for-fast-exploration-of-machine-learning-pipelines
- how-to-test-multiple-machine-learning-pipelines-with-just-a-few-lines-of-python
- from-raw-data-to-web-app-deployment-with-atom-and-streamlit
- exploration-of-deep-learning-pipelines-made-easy
- deep-feature-synthesis-vs-genetic-feature-generation
- from-raw-text-to-model-prediction-in-under-30-lines-of-python
- how-to-make-40-interactive-plots-to-analyze-your-machine-learning-pipeline
- machine-learning-on-multioutput-datasets-a-quick-guide
- using-mlflow-with-atom-to-track-all-your-machine-learning-experiments-without-additional-code
References:
- All plots and images (except the featured image) are created by the author.
