Lineage + Hamilton in 10 minutes
Hamilton is a general purpose open-source micro-framework for describing dataflows. It is great for data & Machine Learning (ML) work. In this post, we're going to walk you through Hamilton's lineage capabilities that can help you quickly answer common questions that arise while working with data & ML, so that you can work more efficiently and collaborate more effectively with colleagues. If you're not familiar with Hamilton we invite you to browse the following:
- www.tryhamilton.dev (interactive in the browser overview)
- Introducing Hamilton (backstory and introduction)
- Hamilton + Pandas in 5 minutes
- Github – https://github.com/dagworks-inc/hamilton
Lineage
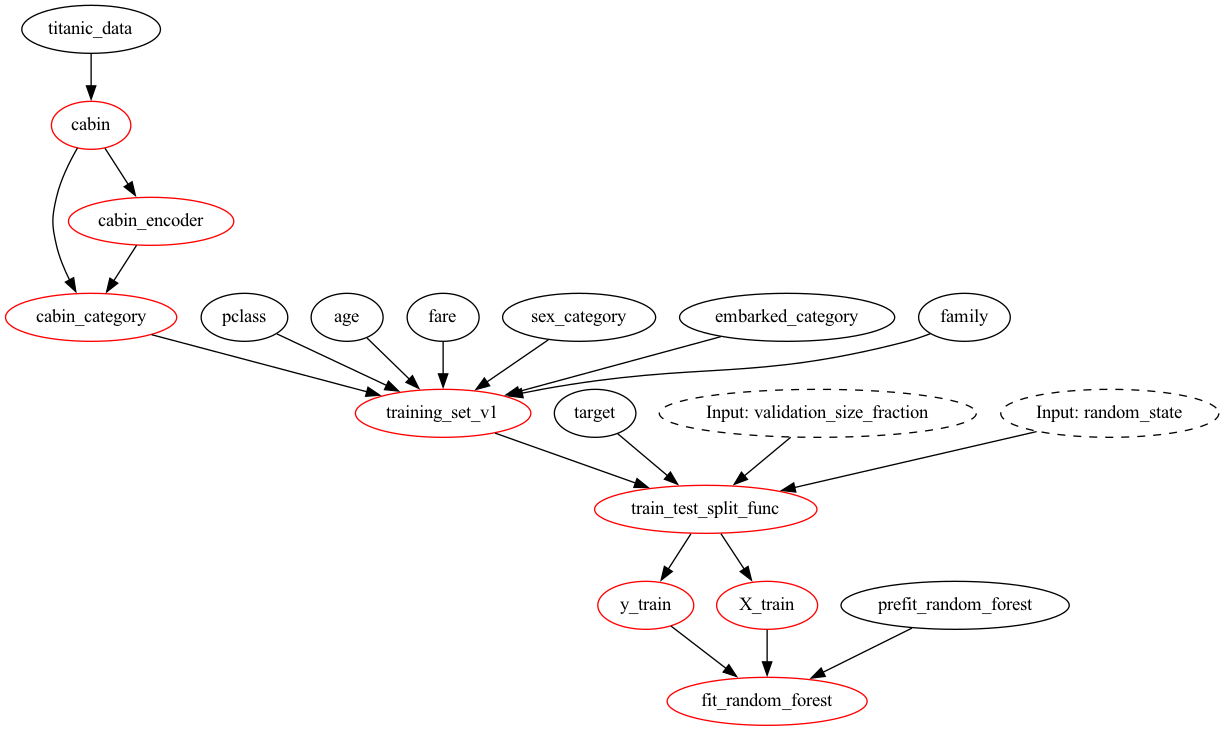
What do I mean by lineage you may ask? In the context of machine learning and data work, "lineage" refers to the historical record or traceability of data as it is transformed and manipulated into things like tables, statistical models, etc. Lineage helps one to determine the provenance, quality, and reliability of "data", as it aids in understanding how data has been transformed.
Why you should care about lineage?
If you're the author of what you have to manage, you probably have a fair idea how everything that you've written connects. But, for someone to inherit your work, or to bring on a collaborator, or having to debug something you wrote six months ago, getting up to speed can be a challenge! I've heard of teams taking over a quarter to understand work a colleague left behind (they're obviously not using Hamilton)! In situations such as these, is where lineage can be a great help. To provide some more context, here are some common situations that result in lost productivity, general unhappiness, and even outages: (a) debugging a data problem with your training set/model (that turned out to be an upstream data issue). (b) trying to determine how someone else's pipeline works (because you inherited it, or have to collaborate with them). (c) having to fulfill an auditing requirement on how some data got somewhere (e.g. GDPR, data usage policies, etc.). (d) wanting to make a change to a feature/column, but not having a good way to assess potential impacts (e.g. the business changed and so did data collected).
Practically speaking, most people working in data and machine learning don't encounter or understand the value of having "lineage" because more often than not, it's a headache to do well. Usually an external system is needed (e.g. open lineage, Amundsen, Datahub, etc), which then needs users to do extra work to populate it with information. The good news is, if you use Hamilton, there isn't the need for another system to get lineage; making use of lineage is straightforward too!
Lineage as Code
With Hamilton, you do not need to add anything else, and you get lineage.

By virtue of writing code in the Hamiltonian way, you are defining computation within functions, and then specifying via function input arguments, how things connect, encoding lineage. Taking this code and connecting with e.g. a version control system (e.g. git), then also provides you with the means to snapshot lineage at points in time! Because you have to update code to change how computation operates, you, by definition, then update lineage without you having to do anything
